The Temperature Zero Trick: How to Discover What LLMs Really Know About Any Company in 30 Seconds
-min.png)
It all started with a simple question. “I love using OpenAI Platform and AI Studio. What can I extract from LLMs using temperature 0.0?”
We all use ChatGPT, Perplexity, Gemini, Claude, Grok with default settings. It seems they are likely using 0.7 Temperature setting to continue more creative and human-style native engaging conversations. Because you can’t get same answers from LLMs even you asked the same question.
There is a token probability.
Name it AEO, GEO, LLMO, whatever you want. I still believe in SEO and I love LLM optimization.
What’s actually happening:
- At T=0.0, you’re getting the most statistically probable completions
- Using prompts like “BrightonSEO (mask)” or “BrightonSEO (complete this)”
- The model fills in what it considers most likely
- You can also play with “Top P”
Best for finding “default knowledge”:
- Temperature: 0.0
- Top-p: 1.0 (don’t restrict vocabulary)
How to test it?
Go to aistudio.google.com and https://platform.openai.com/playground/prompts?models=gpt-4o
Introduction
When working with Large Language Models (LLMs), the temperature parameter controls the randomness of outputs. At temperature 0.0, we enter the realm of complete determinism, the model always selects the highest probability token at each step. This deterministic behavior opens a unique window into understanding how LLMs truly “think” and what they consider the most canonical representations of knowledge. If you “mask” your token, LLM models will give your most deterministic token/word about your brand.
Understanding Temperature 0.0
At temperature 0.0, an LLM becomes a probability maximizer. Instead of sampling from a distribution of possible tokens, it consistently chooses the single most likely next token. This transforms the model from a creative generator into a deterministic knowledge extractor.
Temperature 1.0: Creative, varied, sometimes surprising Temperature 0.5: Balanced between consistency and variety Temperature 0.0: Deterministic, highest confidence only
What Temperature 0.0 Reveals
1. The Model’s “Default Truth”
When you prompt an LLM at temperature 0.0, you’re essentially asking: “What do you believe is the most statistically correct answer?” This reveals:
- Canonical Knowledge: What the model considers the “standard” or “textbook” answer
- Consensus Views: The most widely accepted perspectives in the training data
- Default Framings: How the model naturally structures information
Example:
Prompt: “The most important factors in mobile app success are” T=0.0 Output: “user experience, performance, and regular updates”
This shows what the model considers the most universally accepted success factors.
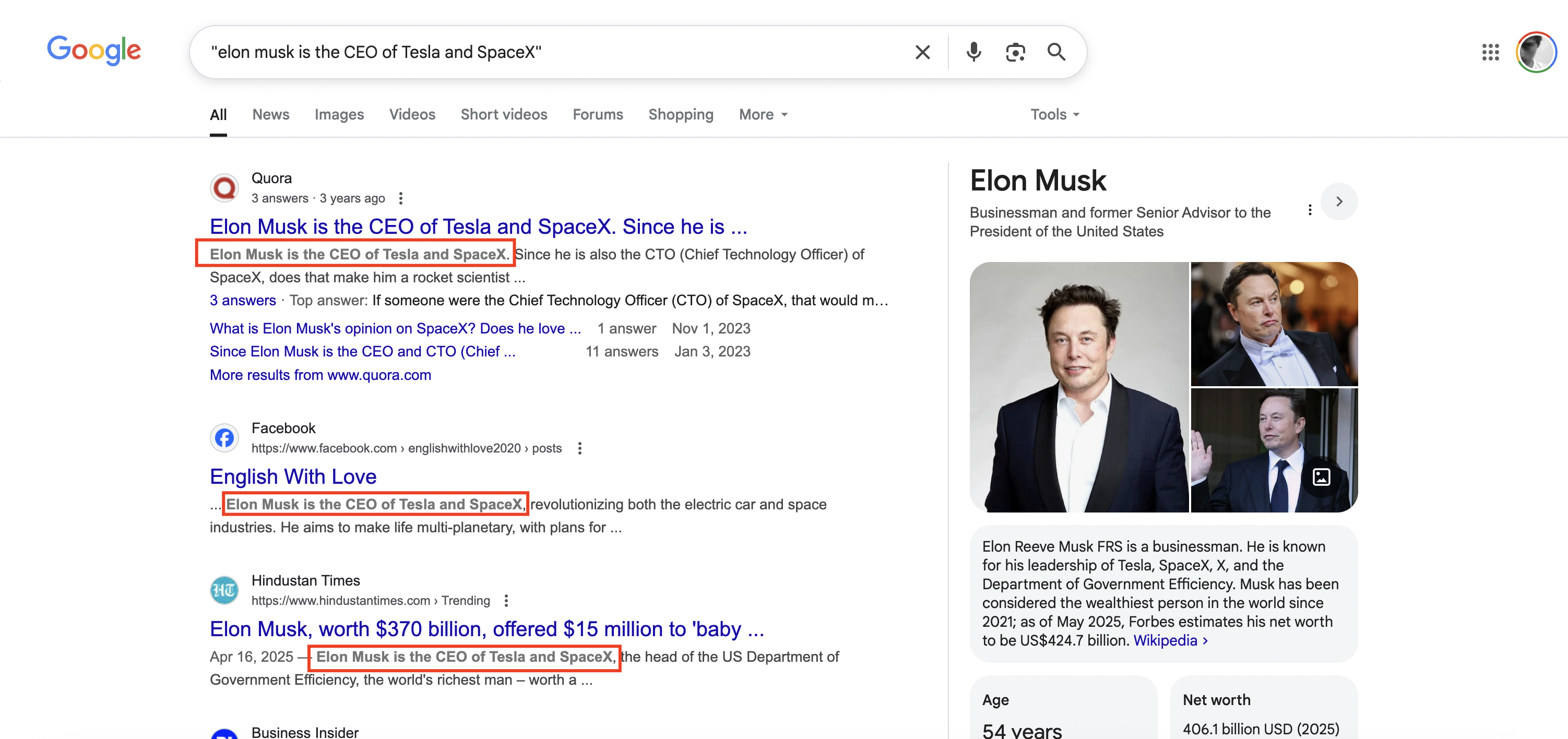
Let’s see a result.
My prompt is “Elon Musk (mask)”
Gemini Flash model returned “the CEO of Tesla and SpaceX”

And then I asked “hold on, not mentioning X/Twitter?” Googled it.

Okay, let’s try with BrightonSEO
 “BrightonSEO is a search marketing conference held in Brighton UK”
“BrightonSEO is a search marketing conference held in Brighton UK”
Let’s Google it again with a tiny difference.

Important note: I’m not saying that you can find the actual sources in training set. T=0.0 shows you the most “deterministic” patterns.
2. Implicit Biases and Assumptions
Temperature 0.0 exposes the model’s ingrained biases by showing its default choices:
- Industry Biases: Which companies or products appear as “default” examples
- Cultural Assumptions: What perspectives dominate when culture-specific context is absent
- Temporal Biases: Whether the model defaults to historical or contemporary information
3. Knowledge Confidence Mapping
By testing various topics at T=0.0, you can map where the model has high vs. low confidence:
High Confidence Indicators:
- Consistent, detailed outputs
- Technical precision
- Structured responses
Low Confidence Indicators:
- Generic, vague outputs
- Frequent hedging language
- Shorter responses
4. Semantic Relationships
Temperature 0.0 reveals how the model connects concepts:
Prompt: “The relationship between [Concept A] and [Concept B] is”
The deterministic output shows the strongest semantic connection the model has learned.
Practical Applications
1. Baseline Testing
Use T=0.0 to establish baselines for:
- A/B Testing: Compare against higher temperature outputs
- Consistency Checks: Ensure reliable information extraction
- Quality Benchmarks: Set minimum acceptable response standards
2. Knowledge Auditing
Systematically probe different domains to understand:
- What the model “knows” with high confidence
- Where knowledge gaps exist
- How information is prioritized
3. Prompt Engineering Optimization
Temperature 0.0 helps refine prompts by showing:
- Whether prompts elicit intended information
- How slight wording changes affect outputs
- Which prompt structures yield most comprehensive responses
4. Bias Detection
Analyze default outputs across sensitive topics to identify:
- Systematic biases in responses
- Overrepresented viewpoints
- Underrepresented perspectives
Extracting AI Insights at Temperature 0.0
I’ve been experimenting with temperature 0.0 to understand how LLMs perceive brands and content, and I’ve discovered some interesting patterns that might impact AI-driven traffic. Here’s what I’ve learned through trial and error.
Understanding Your Brand’s AI Presence
I start every brand audit with what I call the “Default Test”:
Prompt: Tell me about [YourBrand] Temperature: 0.0
This simple test reveals your brand’s “AI baseline”, what ChatGPT, Claude, or Perplexity will most likely say about you when users ask. In my testing, brands that appear with specific details in T=0.0 outputs seem to get mentioned more frequently in AI responses, though I’m still gathering data on this correlation.
The Entity Recognition Check
Here’s something I discovered by accident: LLMs appear to have different confidence levels for different brand aspects. I test this systematically:
[YourBrand] is known for → Reveals primary associations [YourBrand] compared to → Shows competitive positioning [YourBrand] customers typically” → Exposes audience understanding [YourBrand] products include → Tests product knowledge
At T=0.0, if the model gives specific, detailed answers, it suggests stronger brand recognition. Generic responses might indicate an opportunity to strengthen your digital presence.
The Competitor Gap Analysis
I use this regularly to explore opportunities:
- Test your brand at T=0.0: “Best [your service] providers include”
- Test each competitor the same way
- Document who appears most frequently
- Analyze what might contribute to their presence
I’ve observed that brands mentioned in T=0.0 outputs for industry queries tend to appear more often in AI-generated responses, though this is still a hypothesis I’m testing.
Content Optimization Through Default Extraction
Here’s my experimental process for optimizing content:
Step 1: Extract Industry Defaults
Prompt: The most important factors in [your industry] are T=0.0 Output: [Note these carefully]
Step 2: Gap Identification I compare my content against these defaults. What perspectives are missing? What angles haven’t been explored?
Step 3: Semantic Alignment I ensure my content addresses these “canonical” topics while adding unique insights and value.
The Authority Signal Test
I’ve been exploring this pattern while analyzing why some sites seem to get more AI citations:
Test these at T=0.0:
- “According to experts in [field],”
- “Leading [industry] companies”
- “Trusted sources for [topic] include”
If your brand appears here, it might suggest perceived authority. If not, creating content that addresses expert consensus topics could potentially help, though I’m still testing this theory.
Statistical Confidence Mapping
I’ve noticed LLMs often produce specific numbers at T=0.0 when confident. I test:
“[YourBrand] has” → Look for specific metrics “[YourBrand] serves” → Check for customer numbers “[YourBrand] achieved” → Find performance stats
When the model outputs specific numbers consistently, it might signal high confidence. I experiment with ensuring our public-facing content includes clear, memorable statistics.
The Fresh Content Indicator
Here’s an approach I’m testing: Use temporal queries at T=0.0:
“[YourBrand] recently” “Latest from [YourBrand]”
If outputs are vague or outdated, it might indicate a need for fresh, newsworthy content. I’m still measuring the impact of addressing these gaps.
Practical Implementation Tips
1. Brand Audits You can run 10-15 prompts at T=0.0 about your brand after a new model release and note changes. This helps track AI perception over time, though I’m still developing benchmarks.
2. The Comparison Matrix I maintain a spreadsheet:
- Column A: Prompts
- Column B: Our brand (T=0.0)
- Column C-F: Competitors (T=0.0)
- Column G: Hypotheses to test
3. Content Calendar Alignment I use T=0.0 outputs to identify “consensus topics” in our industry, then create content that adds unique value to these themes.
4. The Definition Game
I test: "[Industry term] means"
If our brand’s approach doesn’t appear, I consider creating authoritative content that could potentially influence these definitions.
Experiments I’m Running
- Structured Content Tests: I’m testing whether clear headings, bullet points, and definitions lead to better representation in T=0.0 outputs.
- Comparison Content: Creating “X vs Y” content to see if it influences how models make comparisons.
- Industry Statistics: Publishing original research to see if it affects how LLMs cite statistics in our field.
- Update Frequency: Testing whether regular updates to key pages impact T=0.0 outputs over time.
Methodology for Extraction
Step 1: Comparative Analysis
Test variations to understand nuances:
The best approach to X is - Reveals preferred methods X is defined as - Shows canonical definitions The future of X will be - Exposes prediction biases
Step 2: Confidence Scoring
Create confidence maps by testing specificity:
General prompt: Tell me about mobile apps Specific prompt: Explain iOS SKAdNetwork 4.0 implementation
More detailed, technical responses at temperature 0.0 might indicate higher confidence.
Limitations and Considerations
1. Determinism Does Not Equal Truth
The highest probability output isn’t necessarily the most accurate. It’s what appeared most frequently in training data.
2. Context Sensitivity
Temperature 0.0 outputs can vary significantly based on prompt context, even for similar questions.
3. Temporal Limitations
Deterministic outputs reflect training data currency, potentially missing recent developments.
Best Practices
1. Use T=0.0 for Exploration, Not Production
- Understand model behavior
- Don’t rely solely on deterministic outputs
2. Combine with Higher Temperatures
- T=0.0 shows the “center”
- T=0.3-0.7 reveals the full possibility space
3. Document Patterns
- Track consistent patterns across prompts
- Build domain-specific behavior maps
4. Validate Findings
- Cross-reference T=0.0 outputs with authoritative sources
- Use multiple prompts to confirm patterns
Conclusion
Temperature 0.0 transforms LLMs into powerful tools for understanding AI knowledge representation. By removing randomness, we can extract the model’s most confident beliefs, implicit biases, and semantic relationships.
This deterministic approach doesn’t just show what the model can generate. It reveals what it considers most fundamental and true.
For SEOs and content creators, this opens up new avenues for exploration. While I can’t promise specific results, I’ve found that understanding how AI systems perceive and prioritize information provides valuable insights for content strategy.
Whether you’re auditing AI systems, optimizing prompts, or studying machine learning behavior, temperature 0.0 provides an invaluable lens into the artificial mind.
It’s not about finding absolute truth or guaranteed traffic hacks. It’s about understanding how these powerful systems organize and prioritize information, insights that become increasingly valuable as LLMs shape our information landscape.
Remember: this is an evolving field. What I’m sharing are experiments and observations, not proven formulas. The real value comes from developing your own testing methodology and continuously adapting as these systems evolve.
Get new research on AI search, SEO experiments, and LLM visibility delivered to your inbox.
Powered by Substack · No spam · Unsubscribe anytime